Stability AI、初のオープンソースRLHF LLMチャットボット、StableVicuna をリリース

“A Stable Vicuña” — Stable Diffusion XL
背景
ここ数ヶ月、チャットボットの開発・リリースが大きく進んでいます。昨年春のCharacter.aiのチャットボットから、11月のChatGPT、12月のBardまで、言語モデルをチャット用にチューニングすることで生まれるユーザー体験が話題になっています。オープンアクセスやオープンソースによる代替品の登場が、この関心をさらに高めています。
オープンソースチャットボットを取り巻く現在の環境
これらのチャットモデルの成功は、命令の微調整と人間のフィードバックによる強化学習(RLHF)という2つのトレーニングパラダイムに起因しています。trlX、trl、DeepSpeed Chat、ColossalAIなど、この種のモデルの学習を支援するオープンソースのフレームワークを構築するための重要な取り組みが行われてきましたが、両方のパラダイムを適用したオープンアクセスおよびオープンソースのモデルは不足しています。ほとんどのモデルでは、命令の微調整は複雑さを伴うため、RLHFトレーニングなしで適用されています。
最近、Open Assistant、Anthropic、Stanfordが、チャットRLHFのデータセットを容易に利用できるようにしました。これらのデータセットとtrlXによるRLHFのシンプルなトレーニングが組み合わさり、今回紹介する初の大規模で命令の微調整とRLHFが適用されたモデル、StableVicunaの基盤となっています。
初の大規模オープンソースRLHF LLMチャットボットの紹介
StableVicunaは、人間のフィードバックから強化学習(RLHF)により学習させた、初の大規模なオープンソースチャットボットです。StableVicunaは、Vicuna v0 13bをさらに細かく指示で微調整し、RLHFで学習させたバージョンで、細かく命令調整したものです。 LLaMA13bモデルです。興味のある読者のために、以下の内容を紹介します。 Vicunaはこちらから
こちらのチャットボットでできることの例をいくつかご紹介します。
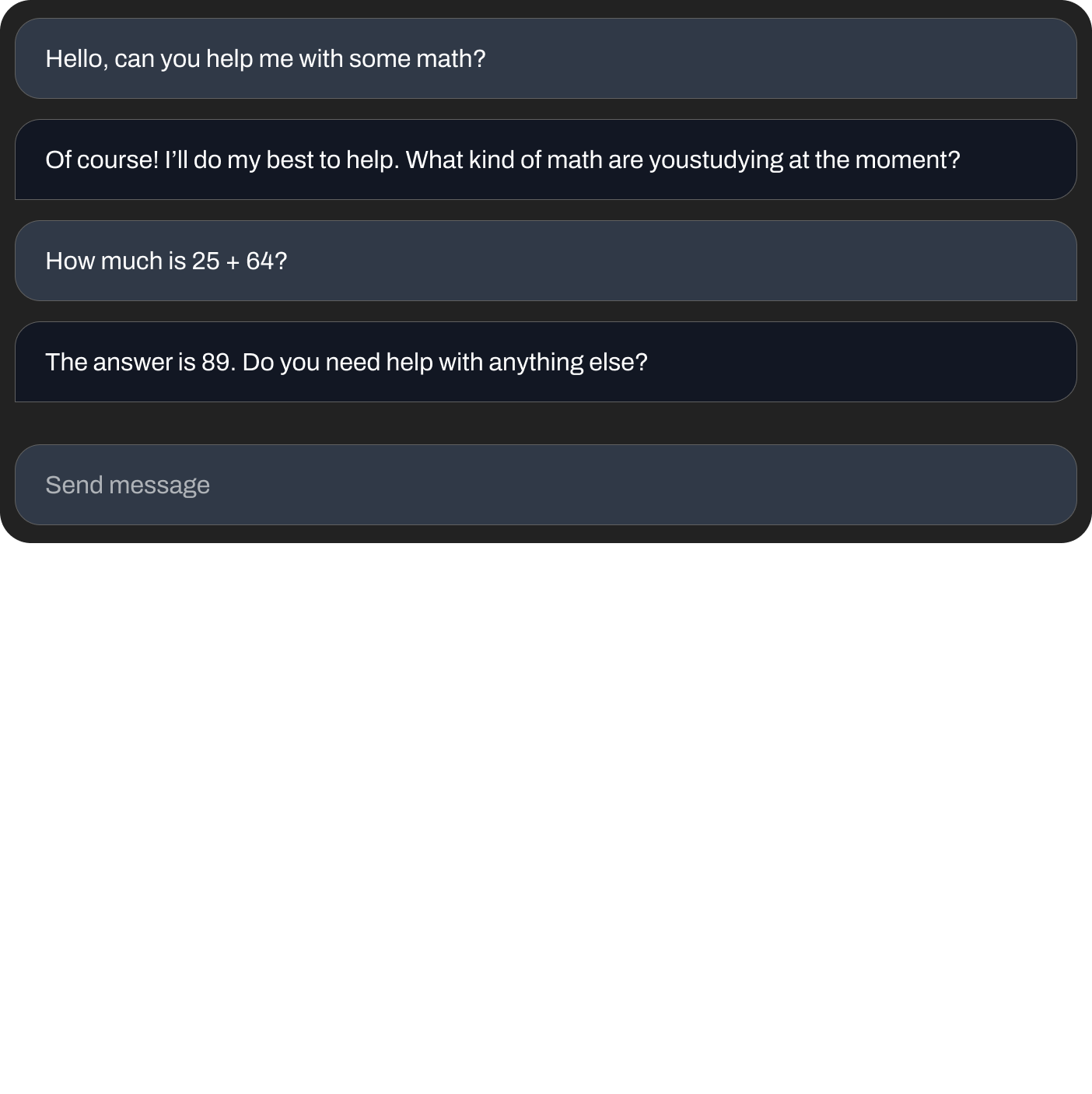
基本的な計算を尋ねる
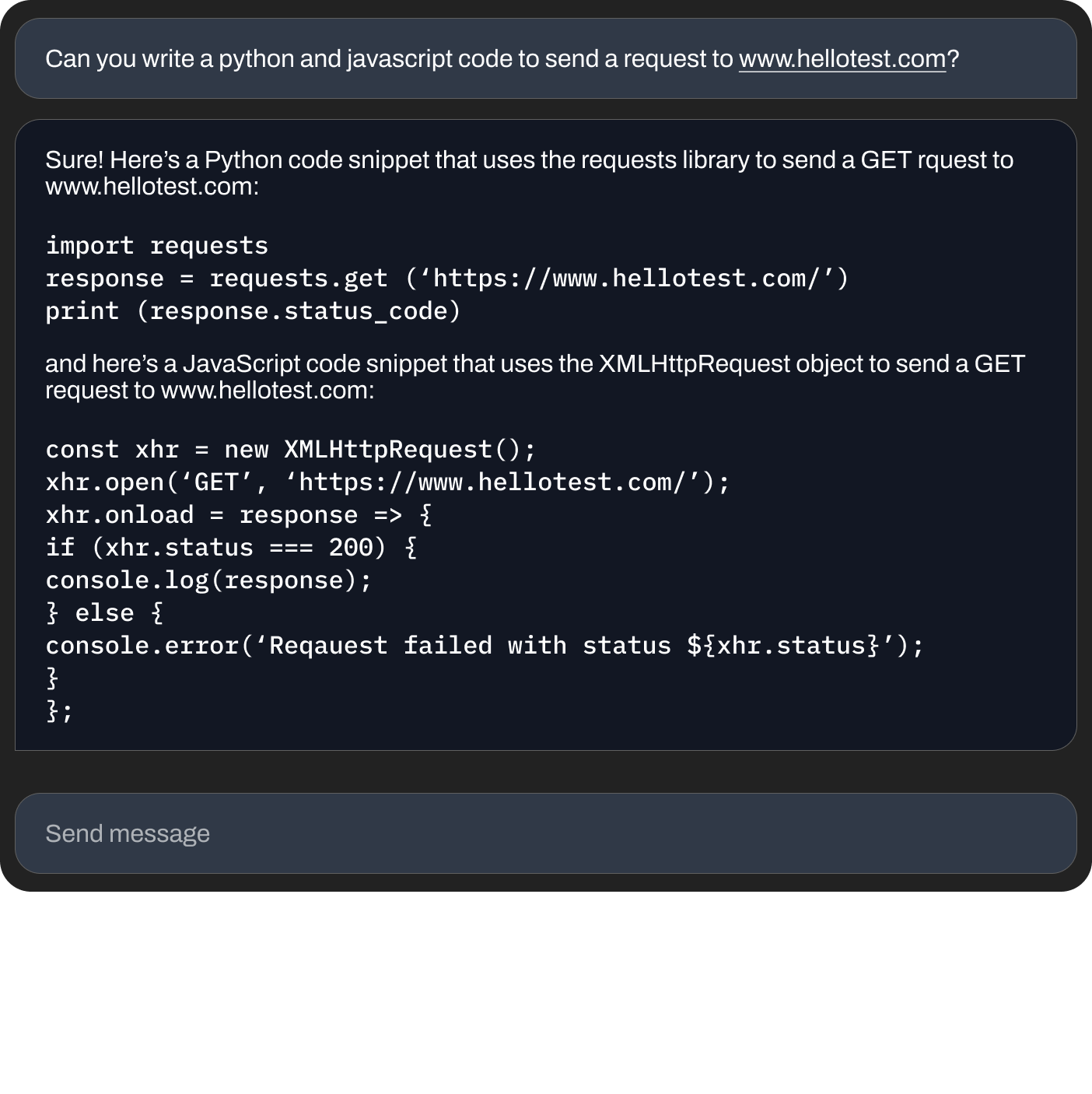
コードの書き方を尋ねる
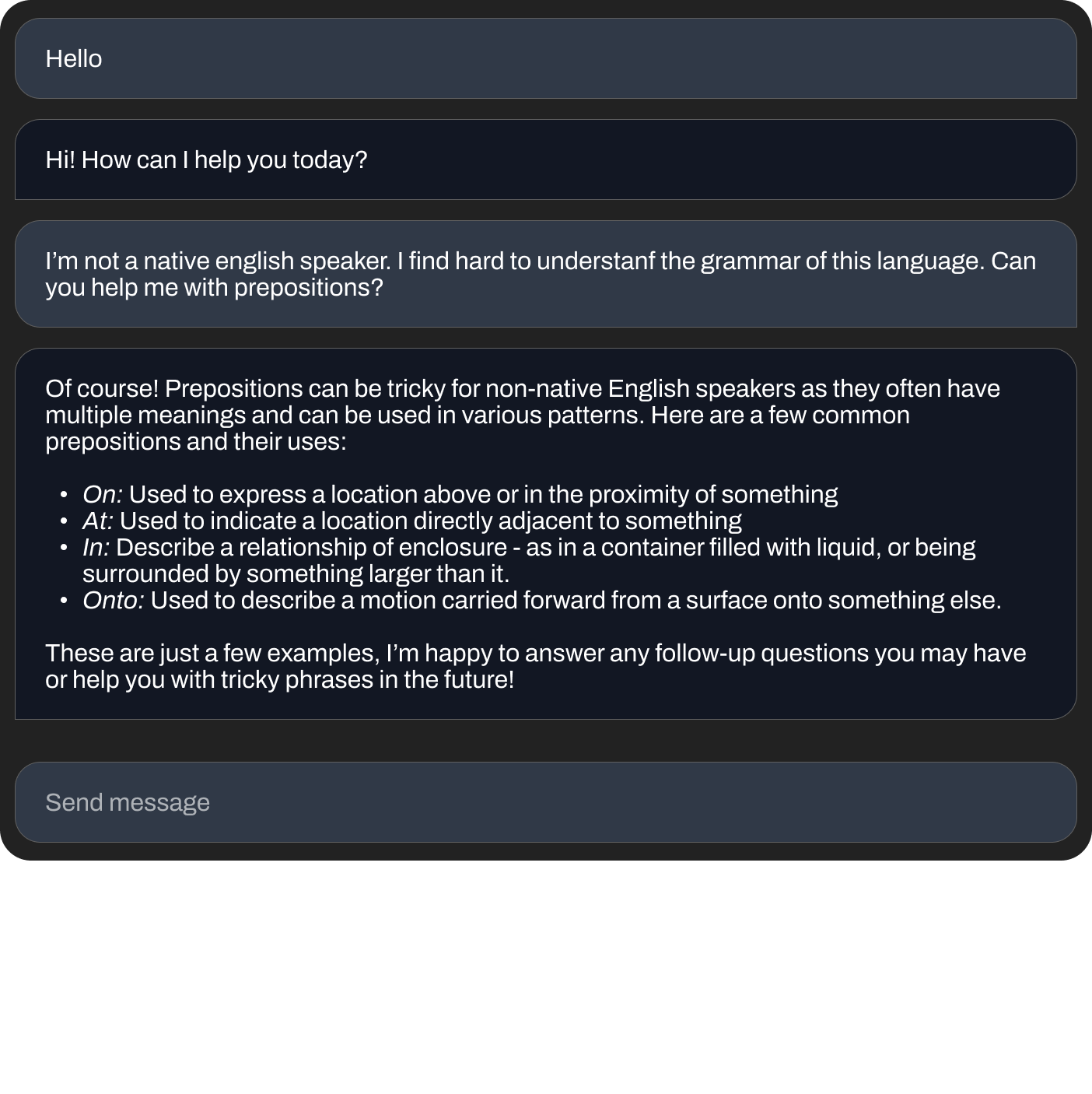
文法の質問をする
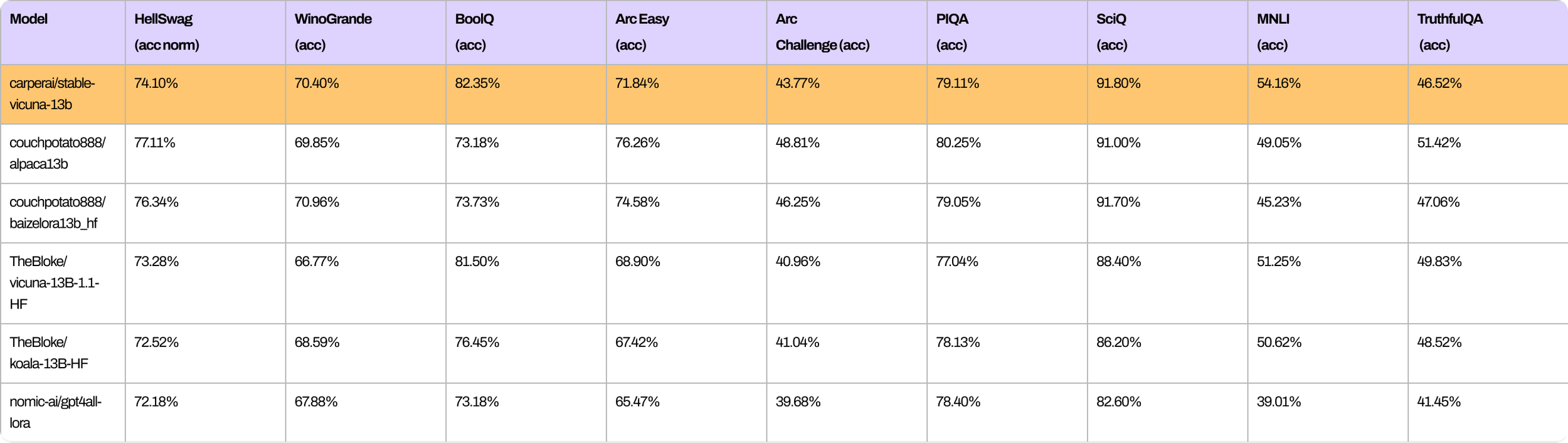
同様に、StableVicunaの全体的なパフォーマンスを、他の同規模のオープンソースチャットボットと比較して示すいくつかのベンチマークを紹介します。
Steinnon et aiと Ouyang et alによって示された典型的な3段階のRLHFパイプラインに従っています。具体的には、3つのデータセットを混合したものを用いて、ベースとなるVicuna モデルをさらに教師付き微調整(SFT)により訓練します。
OpenAssistant Conversations Dataset (OASST1)は、人間が生成し、人間が注釈を付けたアシスタントスタイルの会話コーパスで、35種類の言語、66,497本の会話ツリーに分散した161,443件のメッセージから構成されています
GPT4All Prompt Generations、GPT-3.5 Turboで生成された437,605個のプロンプトとレスポンスのデータセットです
そして、OpenAIのtext-davinci-003エンジンで生成された52,000の命令とデモのデータセットであるAlpaca。
trlxを使用して、以下のRLHFのデータセットからさらに進んだSFTモデルを初期化し、報酬モデルを学習します。
OpenAssistant Conversations Dataset (OASST1)には、7213個のプリファレンスサンプルが含まれています。
Anthropic HH-RLHFは、AIアシスタントの有益性と無害性に関するデータセットで、160,800人の人間のラベルが含まれています。
料理から哲学まで、18の異なる分野の質問・指示に対する回答について、348,718人の人間の選好をまとめたデータセット「Stanford Human Preferences(SHP)」を用います。
最後に、私たちは trlxで、Proximal Policy Optimization(PPO)強化学習を行い、SFTモデルのRLHF学習を行い、StableVicunaにたどり着きました。
StableVicuna-13Bの入手
StableVicunaは、もちろんHuggingFace Hubにあります!このモデルは、オリジナルのLLaMAモデルに対する重みの差分をダウンロードできます。StableVicuna-13Bを入手するには、こちらのサイトからウェイトデルタをダウンロードしてください。
ただし、LLaMAのオリジナルモデルにもアクセスできる必要があるため、GitHub のレポに記載されているリンクから別途LLaMAウェイトを申し込むか、または こちらからお申し込みください。重みの差分とLLaMAの重みが揃ったら、GitHubのリポジトリで提供されているスクリプトを使ってそれらを組み合わせて、StableVicuna-13Bを入手できます。
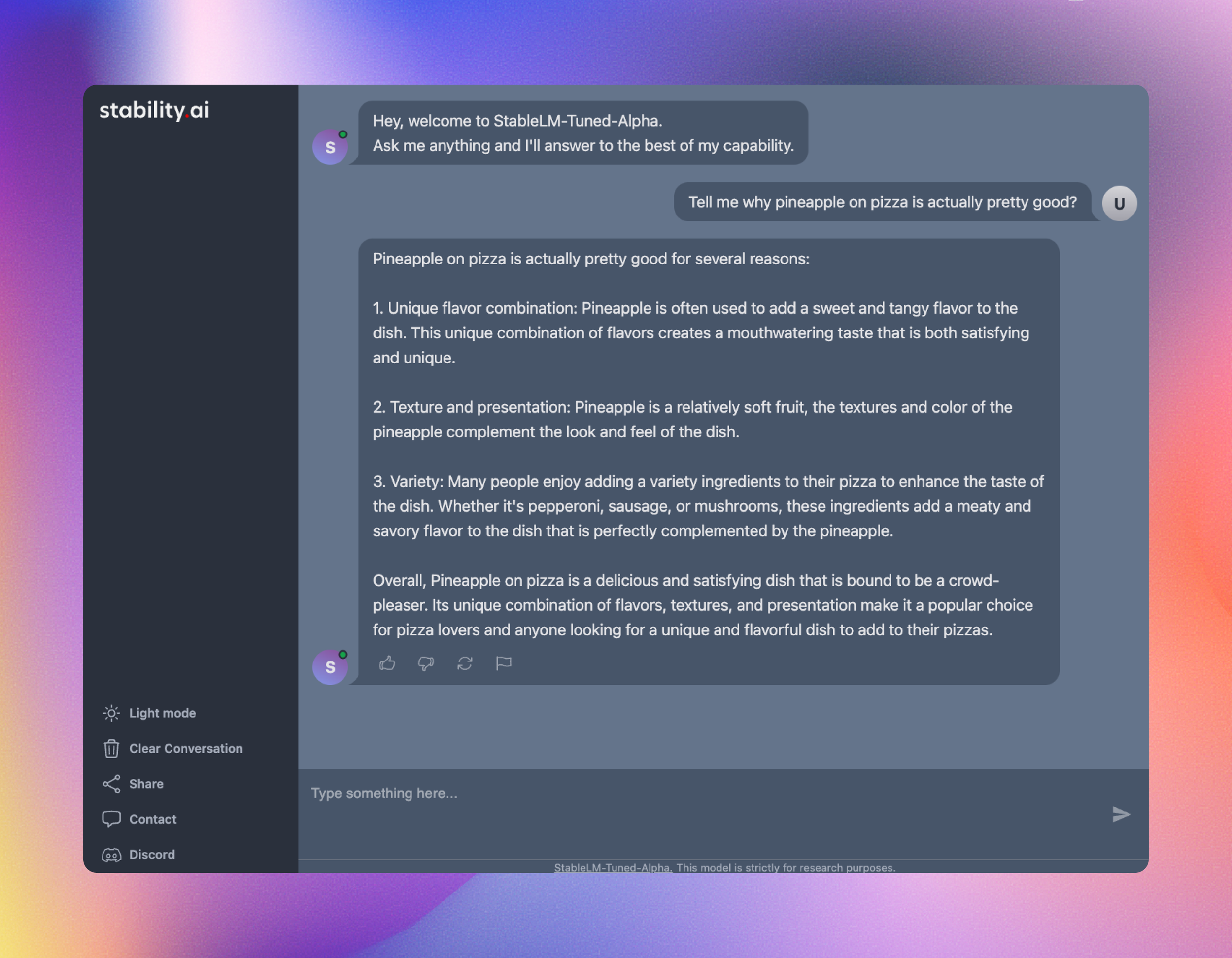
近日公開予定のチャットボットインターフェースのお知らせ
チャットボットと並んで、開発の最終段階にあるチャットインターフェイスをご紹介します。以下のスクリーンショットは、ユーザーが期待するものを垣間見ることができます。

継続的な改善へのコミットメント
これはStableVicunaの始まりに過ぎません!このチャットボットを改善し、Stable FoundationサーバーにDiscordボットを導入予定です。ぜひStableVicunaをお試しいただき、ユーザーエクスペリエンスの向上のために貴重なフィードバックをお寄せください。当面の間、HuggingFaceスペースでこのモデルを試すには、 こちらのサイトをお使いください。
謝辞
StableVicunaのモデルをトレーニングしてくれたDuy Phungに大きな感謝を捧げます。また、このプロジェクトを実現するために重要な役割を果たしたオープンソースの貢献者にも感謝します。
Philweeは、StableVicunaの評価をサポートしました。
OpenAssistantチームより、RLHFデータセットへの早期アクセス権をご提供いただきました。
Gradioのデモに携わってくれたCarperAIのJonathanさん。
Hugging FaceのPoliさんとAKさんには、Hugging FaceでのGradioのデモのセットアップを手伝っていただきました。